你的貼文要被拿去訓練 AI!臉書宣佈 6/26 更新隱私政策,該怎麼拒絕一次看
據《PCWorld》報導,Facebook宣佈將於6月26日更新隱私政策,公開貼文將被用於訓練Meta的AI服務,本文提供反對拒絕 Facebook AI用途的教學,目前台灣用戶並未收到相關通知。

更新:《中央社》記者已於 5 月 31 日詢問 Meta 官方,這項措施是否包含台灣用戶以及提出異議的步驟,至發稿為止尚未取得回覆。
Facebook 宣佈 6/26 更新隱私政策,公開貼文將被拿去訓練 AI
隨著 AI 生成式工具持續發展,各大科技公司也搶著進場。手握臉書(Facebook)、Instagram、Threads 平台的 Meta,近期也推出了 Meta AI 工具(台灣尚不可用),但用於訓練 AI 的資料來源卻引發了爭議。
據電腦設備媒體《PCWorld》報導,Facebook 宣佈自 2024 年 6 月 26 日起,將更改有關 Meta AI 等生成式功能的隱私政策。屆時 Meta 將可瀏覽用戶的貼文和照片,並用來訓練 Meta AI 相關產品。
據悉,部分地區用戶(主要是歐洲國家)已經收到通知,但台灣尚未收到,可能是 Meta 單純尚未通知,或者尚未決定把台灣用戶的公開貼文與照片數據拿來訓練 AI。
外媒指出,Meta 用戶有權拒絕 Facebook 把你的貼文內容拿去訓練 AI,但 Meta 仍會審慎評估你的反對意見。此外,即使你成功拒絕,在某些特定情況下,Meta 仍會使用你的一小部分內容,例如當其他人公開分享你的貼文內容或在貼文中提到你的時候。
Facebook 的 AI 隱私政策內容有哪些?
Meta 究竟會拿哪些照片、貼文去訓練?目前已知只有公開(開地球)的貼文和圖像會受到影響,但私人內容不會被拿去利用,以下是受影響的 3 項內容:
- Facebook 上的公開貼文
- 公開 PO 出的照片與照片描述
- 從 Facebook 發送給 AI 機器人的訊息
《PCWorld》表示,Meta 提到如果用戶有異議,需要在 6 月底之前填寫表單,表達拒絕提供資料的立場。
出於隱私權與個人原因,許多用戶可能不樂見這種事。尤其是對於創作者來說,即便發表的創作內容是公開的,也不代表作品可以被 Meta 隨意利用。
此外,雖然 Meta 聲稱用戶有拒絕的權利,但音樂 YouTuber、音樂廠牌 Mu.se 產品副總裁 Tantacrul 就吐槽,雖然 Meta 有展示隱私政策相關內容,但僅以超連結藍字凸顯拒絕權(right to object)一字,而不是像關閉(Close)那樣的醒目按鈕,這讓他感到很不滿。
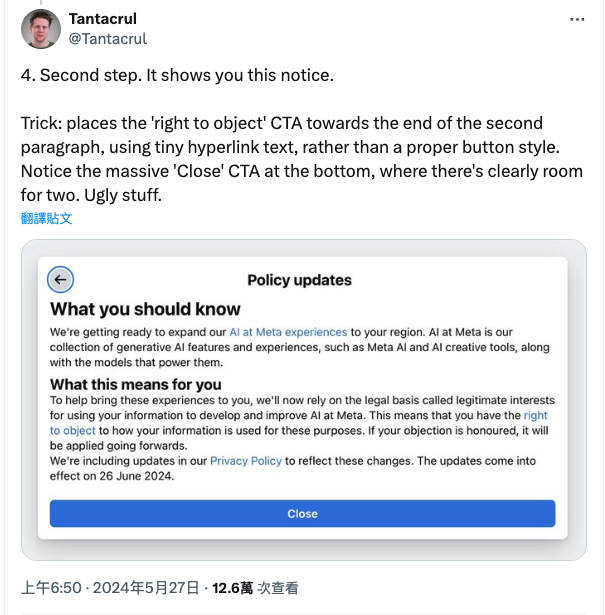
Facebook 宣佈 6/26 更新隱私政策,公開貼文將被拿去訓練 AI
如何拒絕 Facebook 用你的資料去訓練 AI?
不想要讓 Facebook 抓你的資料去訓練 AI 嗎?Tantacrul 分享了填寫表單的步驟。
注意:以下教學步驟僅供參考,因目前尚未有台灣 Facebook 用戶反應收到 Meta 的通知。若 Meta 也確定更新台灣用戶隱私政策並提供提出異議的步驟,屆時將再更新。
- 步驟一:進入 Facebook Meta AI 幫助頁面
- 步驟二:選擇符合你需求的選項
- 第一個選項:「我希望訪問、下載或更正任何來自第三方並被用於在 Meta 建立和改進 AI 的個人資訊。」
- 第二個選項:「我希望刪除任何來自第三方並被用於在 Meta 建立和改進 AI 的個人資訊。」
- 第三個選項:「我對來自第三方的個人資訊有疑慮,這些資訊跟我從 Meta 的 AI 模型、功能或體驗中收到的回應有關。」
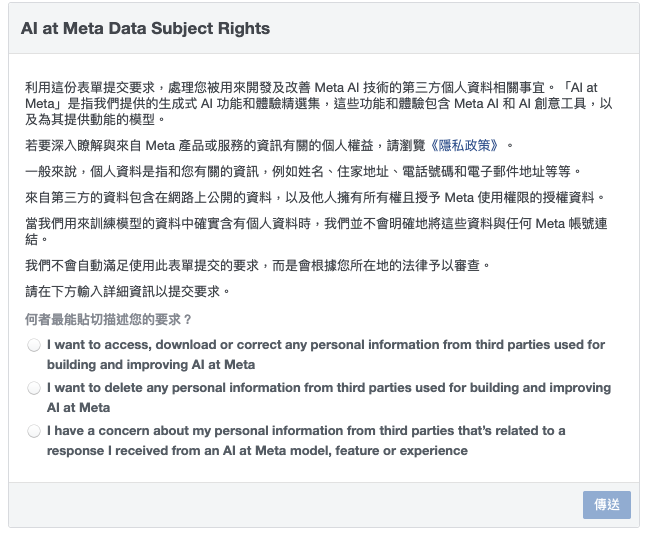
- 步驟三:填寫基本資料、反對提供資料的理由
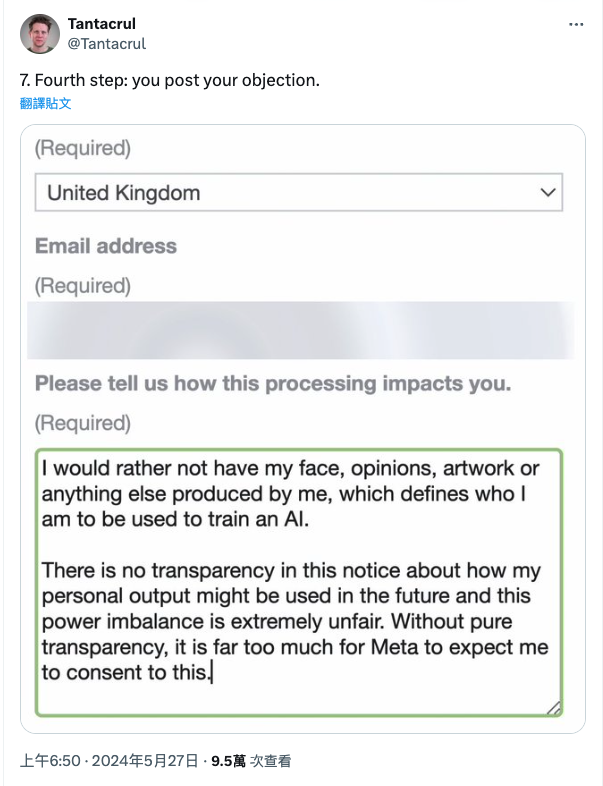
接著就是填寫國家、姓名與 E-mail 資訊,以及反對提供資料的理由。Tantacrul 提出的理由是:
「我不希望我的臉、觀點、藝術作品或任何其他由我創作的、能定義我個人的內容被用於訓練 AI。這份通知缺乏透明度,無法讓我了解我的個人產出將如何在未來被使用,這種權力不平衡是極其不公平的。在透明度不夠的情況下,Meta 要求我同意這一點實在是過分了。」
- 步驟四:收取 E-mail 驗證碼
- 步驟五:收到 Meta 確認收到回覆的消息
Tantacrul 表示,點擊 OK 後不久,在 E-mail 那邊也會收到一封從 Meta 寄來的信件。
Meta 五月初就已透露會採用貼文、照片資料
科技公司採集各種網路公開資料,並餵給 GPT、Midjourney 等 AI 模型訓練似乎已經不足為奇。據《Business Insider》報導,早在 Facebook 發送通知之前,Meta 就已經透露會使用 Facebook、Instagram 用戶的公開照片。
5 月 9 日,Meta 產品長 Chris Cox 在彭博科技高峰會上表示,正在使用平台上公開的照片與文字來訓練文字圖像生成工具 Emu,並強調不會對私人內容出手,例如僅自己可見或朋友可見的內容。
AI 模型需要被餵資料和訓練才能發揮作用,而 ChatGPT、BingAI、Grok 等產品確實在某種程度上加快了人類的工作效率。然而,目前幾乎沒有法規能夠阻止版權著作被人隨意抓取,並用於訓練 AI。
自 2023 年初以來,美國著作權局一直企圖解決這個問題,並正在考慮修法。然而,已有一些創作人士透過司法程序來表達不滿,讓 AI、著作權之間的爭鬥備受關注。



你可能想知道
